Schema Markup Is Not Enough: What Generative Engine Optimization Actually Requires in 2026

There is a version of Generative Engine Optimization being sold right now that goes something like this: an agency audits your website, identifies that you are missing Schema markup, implements Organization, Service, and FAQ JSON-LD in 72 hours, validates it with Google's Rich Results Test, and hands you a report showing green checkmarks. They tell you that AI engines will begin recommending you within one to two weeks as crawlers re-index your site. The invoice is $3,000. The deliverable is clean code. The promise is AI visibility.
Schema markup is necessary. Every serious GEO engagement begins with it. But stopping at Schema is like filing your business with the state and then wondering why no customers walk through the door. You exist on paper. That does not mean anyone knows you exist, respects what you do, or would recommend you to someone asking for help. The "72-hour GEO sprint" has become the industry's equivalent of keyword stuffing in 2009: a technically valid tactic sold as a complete strategy by agencies that either do not understand the full picture or find it inconvenient to explain.
I am writing this because I used to frame GEO the same way. The technical fix was clean, deliverable, and easy to sell. It was also incomplete. What changed was spending enough time testing AI recommendations across real client categories and watching businesses with flawless Schema remain completely invisible while competitors with messier code but broader web presence dominated every query. The data forced the correction. Schema is the foundation. It is not the building.
What Schema Actually Does
Schema markup is structured data embedded in a website's code that communicates facts about a business in a format AI crawlers can read without interpretation. When a properly implemented Schema block tells an AI crawler that this website belongs to an Organization named "Apex Financial Advisors," that this organization offers "Retirement Planning" and "Estate Planning" services, that it is located in Denver, Colorado, that its founder holds a CFP certification, and that it has published answers to frequently asked questions about wealth management, the crawler receives a clean data packet it can index with high confidence.
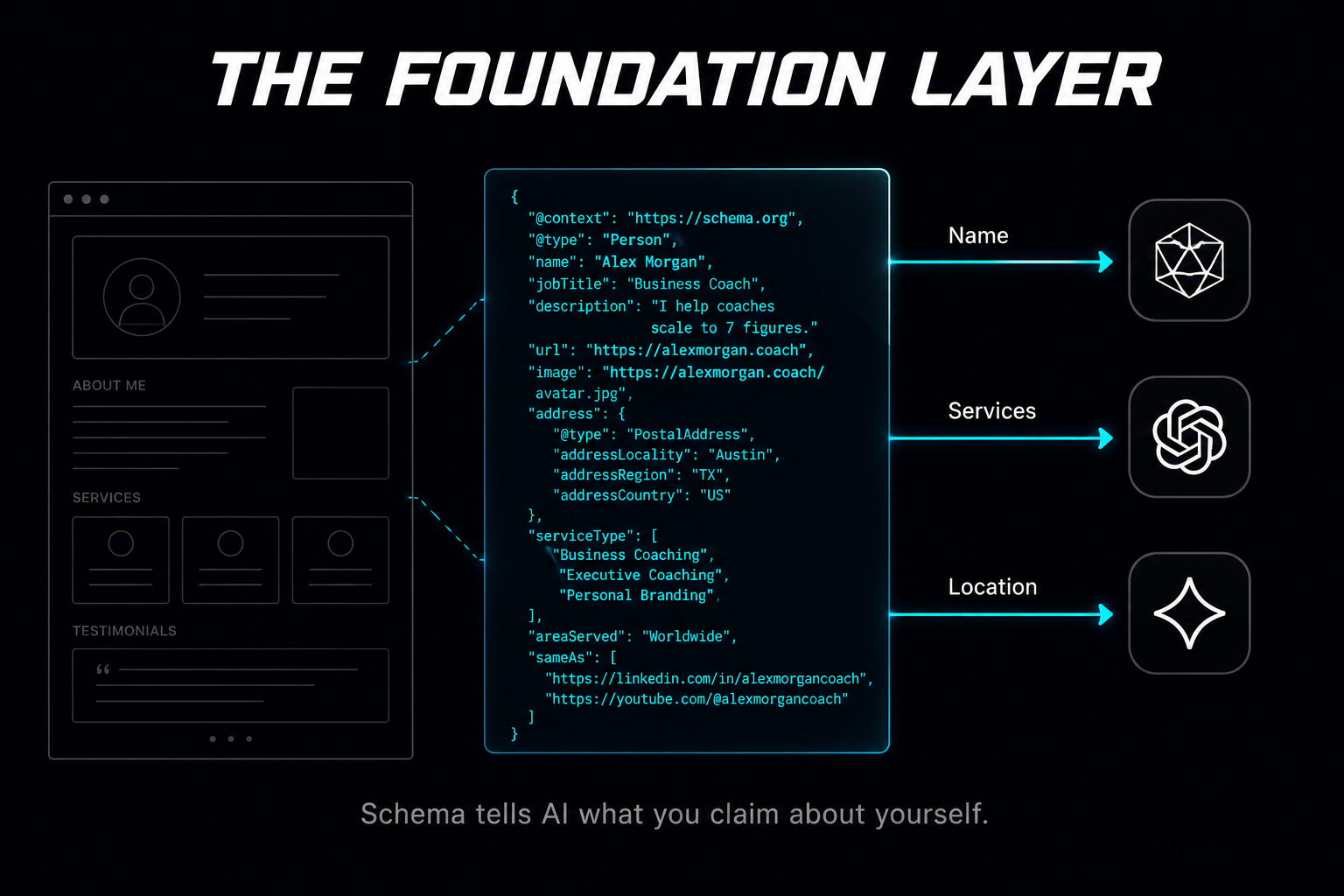
This matters. Without Schema, the AI must infer all of this from unstructured text, which introduces ambiguity. Is "Apex" a financial advisory firm or the name of a fitness program? Does this business serve Denver specifically or is Denver just mentioned in a blog post? Schema removes the guesswork and gives the AI verified, structured assertions about identity, services, and scope.
But here is what Schema does not do. It does not tell the AI whether anyone else on the internet agrees with those assertions. It does not tell the AI whether real clients have discussed this business in public forums. It does not tell the AI whether independent publications have recognized this business as noteworthy. It does not tell the AI whether the business has been mentioned in comparison articles, referenced on podcasts, or cited in Reddit threads where real people share real opinions. Schema is a self-declaration. AI models are specifically designed to not rely solely on self-declarations when making recommendations.
How AI Actually Forms Recommendations
Large language models like ChatGPT, Claude, Perplexity, and Gemini form their recommendations through a process that synthesizes signals from across the entire web, not from any single website. Understanding what those signals are explains why Schema alone fails.
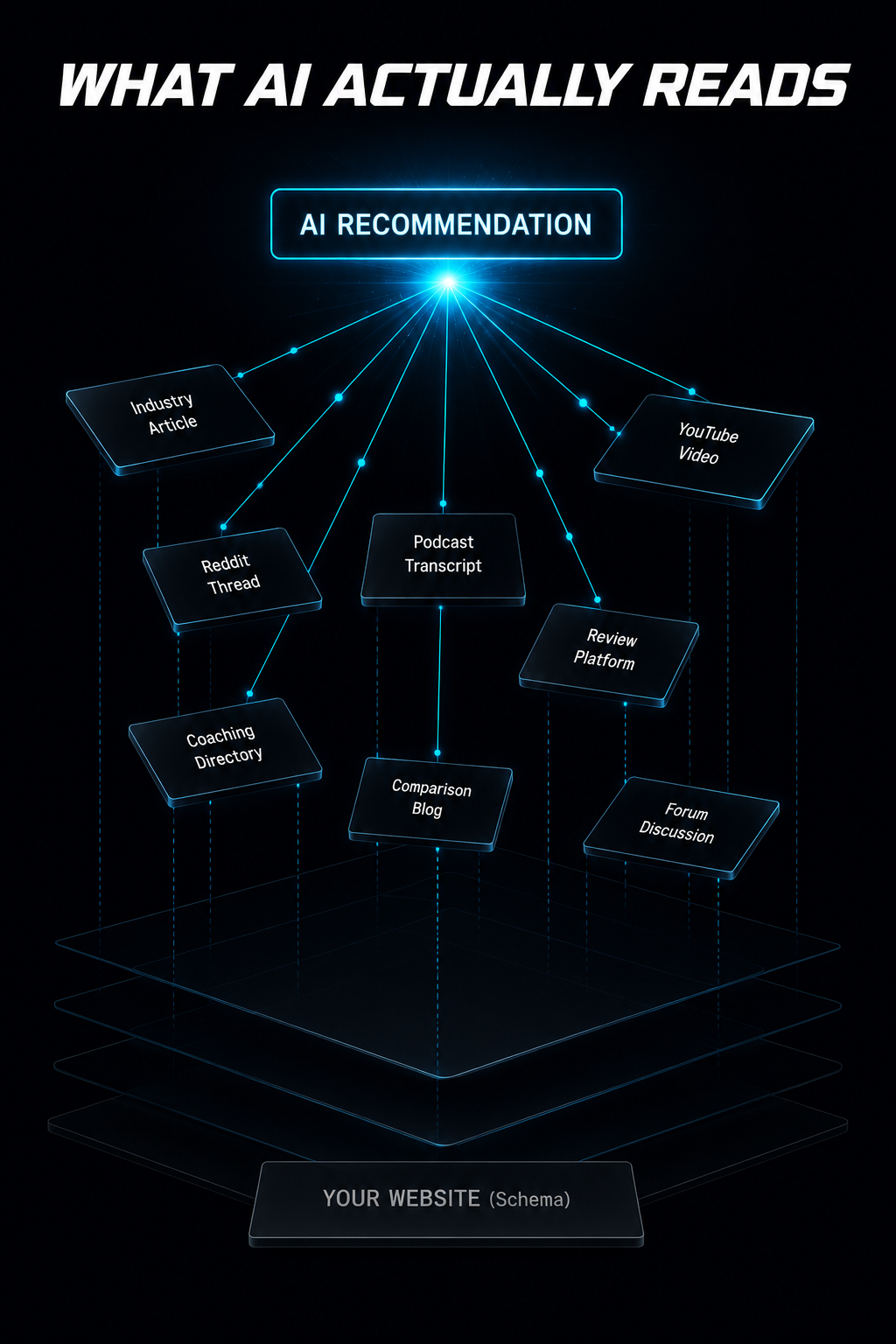
Third-party mentions are the heaviest signal. When a brand appears in a roundup article on an industry publication ("The Top 8 Financial Advisors in Denver for High-Net-Worth Clients"), that mention exists on a domain the AI considers authoritative and independent. When the same brand appears in a review on a platform like Clutch, Trustpilot, or a niche directory, that is another independent data point. When a journalist or blogger references the brand in a comparison piece, that is another. Each mention does not need to be a glowing endorsement. It simply needs to exist in a relevant context on a credible source. The AI is looking for citation consensus: multiple independent sources converging on the same association between a brand and a category. Ten independent mentions of "Apex Financial Advisors" in the context of "Denver wealth management" carry more weight than a perfectly structured Schema block that says the same thing from the business's own domain.
Reddit and forum discussions carry a specific kind of weight that formal publications do not. AI models, particularly ChatGPT and Perplexity, reference discussion platforms heavily because they contain unfiltered, conversational opinion that reflects how real people actually talk about products and services. A Reddit thread titled "Has anyone worked with a business coach for scaling past $2M?" where a user mentions a specific coach by name and describes their experience creates a citation signal that no amount of Schema markup can replicate. These are organic, unsolicited mentions in contexts the AI treats as authentic social proof.
YouTube content and podcast appearances create multimedia authority signals. Video transcripts are indexed by Google's Gemini and referenced by Perplexity when it cites video sources. A coach who appears as a guest on a respected podcast generates a mention on the host's website, in podcast directory descriptions, in Apple Podcasts metadata, and across social media shares of the episode. Each of these creates a distinct citation node that the AI observes. A 45-minute podcast interview generates more citation surface area than a month of social media posts.
Blog content and comparison articles that a business publishes on its own domain contribute to content depth. This is the material the AI extracts and cites when answering specific questions. When someone asks Perplexity "What is the difference between fiduciary and non-fiduciary financial advisors?" the AI pulls from the best-structured, most informative content it can find. If a business has published a detailed, well-organized article addressing that exact question, the business becomes a source the AI both cites and recommends. But this content works in tandem with the external signals. Content depth without external validation is just a well-written website that no one else references.
Entity integrity across platforms ties everything together at the data level. The business must appear consistently on Google Business Profile, LinkedIn, Crunchbase, industry-specific directories, and any other platform the AI cross-references. Discrepancies in name, address, services, or descriptions create uncertainty in the AI's entity resolution process. If LinkedIn says the business was founded in 2018 and the website says 2019, the AI cannot resolve the conflict and may downweight the entity's reliability.
And then there is Schema markup. The foundation layer. The structured data that confirms the business's identity in machine-readable format. Necessary. Valuable. The starting point, not the finish line.
Why the Schema-Only Approach Fails
The failure mode is straightforward. A business implements perfect Schema. The JSON-LD is clean, validated, and comprehensive. The AI crawler visits the site, indexes the structured data, and now knows that this business exists, what it does, and where it operates. Then the AI receives a user query: "Who are the best executive coaches in Chicago?" The model searches its knowledge for entities matching that description. It finds the Schema-declared entity. It also finds six other entities that have Schema declarations plus dozens of independent mentions across industry articles, Reddit discussions, podcast appearances, and comparison blogs. The model recommends the entities with the broadest corroboration. The Schema-only business is filtered out. Not because its data was wrong. Because its data was uncorroborated.
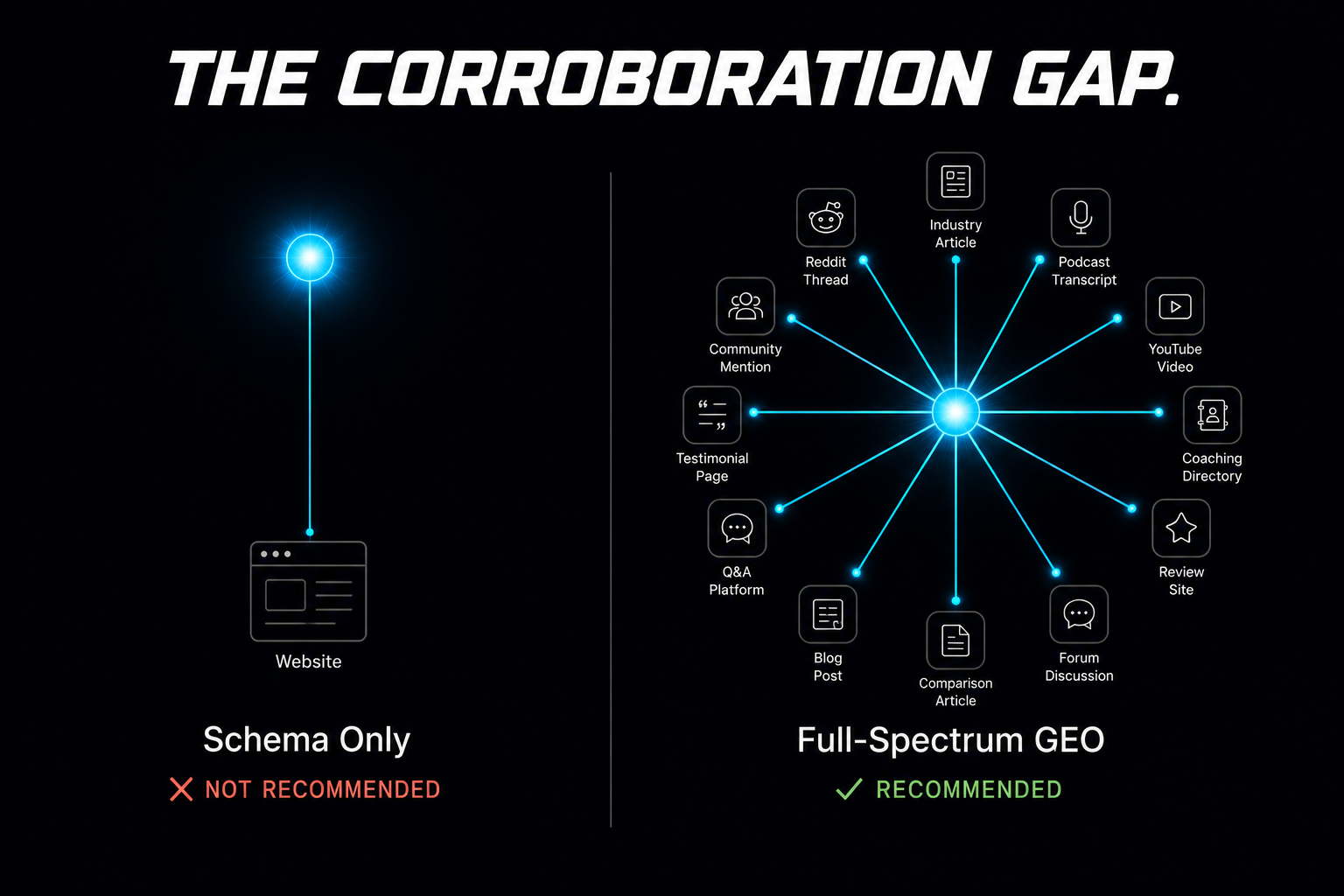
This is the dynamic that the "72-hour sprint" agencies either do not understand or choose not to disclose. They deliver a real, technically valid service. The Schema is correct. The Rich Results Test shows green checkmarks. The client feels like something concrete was accomplished. But the Schema was never the bottleneck. The bottleneck was that no one else on the internet talks about this business in the context of its category. The Schema told the AI what the business claims about itself. The empty web surrounding that claim told the AI there is no independent reason to believe it.
The analogy holds: a resume with the right credentials gets you into the applicant tracking system. It does not get you the job. References get you the job. A track record gets you the job. People who vouch for you without being asked get you the job. Schema is the resume. The citation web is everything else.
What a Complete GEO Engagement Actually Looks Like
The work divides into three phases, each operating on a different timeline and addressing a different layer of the AI's decision-making process.

Phase 1 is technical infrastructure. This is where Schema implementation lives, alongside entity profile creation and optimization across platforms like Google Business Profile, Crunchbase, LinkedIn, and relevant directories. This phase also includes content structure optimization on the website itself: ensuring headings are clear, FAQ content is well-organized, and service descriptions use the specific, unambiguous language that AI models prefer over vague marketing copy. This work takes days. It is the necessary foundation that makes the business machine-readable.
Phase 2 is citation engineering. This is the sustained, multi-channel effort that builds the web of independent signals AI models rely on. It includes getting the brand mentioned in relevant industry articles and roundup posts. It includes building an organic presence on Reddit and forums where the brand's category is actively discussed. It includes publishing comparison content and methodology articles that AI systems can cite as authoritative sources. It includes YouTube content that feeds into Gemini and Perplexity's video index. It includes guest podcast appearances that generate mentions across multiple platforms simultaneously. At Indexis, this phase typically spans 6 to 12 weeks and represents the majority of the work and the majority of the impact. The timeline depends on how invisible the brand currently is. A business that already has some third-party mentions needs less net-new citation building than one that exists only on its own website.
Phase 3 is monitoring and iteration. AI models update their knowledge continuously as they re-crawl the web. A GEO engagement is not a one-time implementation that never needs attention. It requires periodic testing of how AI platforms respond to relevant queries, identifying gaps where competitors have stronger citation signals, and building additional content or citations to address those gaps. This phase is lighter than Phase 2 but it is ongoing. The businesses that maintain their AI visibility are the ones that continue to generate fresh signals, not the ones that implemented Schema once and assumed the work was done.
The Maturation of GEO
The Generative Engine Optimization industry is undergoing the same evolutionary compression that SEO experienced over the past two decades, but on an accelerated timeline. SEO began as keyword stuffing. Agencies charged for meta tag optimization and keyword density calculators. Then the market matured. Google's algorithms became sophisticated enough that keyword manipulation stopped working, and the agencies that survived were the ones that pivoted to genuine content strategy, authority building, and technical excellence. The keyword stuffers were exposed and marginalized within a few years.
GEO is on the same trajectory. The current phase is dominated by agencies selling Schema implementation as a complete solution, the same way early SEO agencies sold meta tags as a complete solution. This approach works just well enough in the current moment that clients do not immediately recognize the gap. But as AI models become more sophisticated in how they weight and verify entity signals, and as more businesses implement basic Schema (reducing its differentiating value), the agencies that only deliver the technical layer will find their clients plateauing or declining in AI visibility despite having "done GEO."
The agencies that survive the shakeout will be the ones that understood from the beginning that GEO is not a code deployment. It is the construction of a digital presence that is broad enough, deep enough, and independently corroborated enough that AI models treat the brand as a default recommendation in its category. Schema is where that process starts. It is not where it ends. The businesses that internalize this distinction now, while the market is still forming and the recommendation slots in most industries are still open, will be the ones that occupy those slots when the window closes.
Sumedh is the founder of Indexis, a Generative Engine Optimization agency that builds full-spectrum AI visibility campaigns for high-ticket service businesses. He can be reached at getindexis.com or sumedh@getindexis.com.